Why latent bandits?
Context alone is not enough
A single observed context can be noisy and incomplete. The optimal action may depend on a stable latent state that only becomes clear across repeated observations.
Leveraging observational data for personalized decision-making
For many chronic diseases, treatment is individualized and sequential: patients go through a long process of trying different options over time:
How can we use observational data to shorten treatment times?
Why latent bandits?
A single observed context can be noisy and incomplete. The optimal action may depend on a stable latent state that only becomes clear across repeated observations.
Why identifiability?
A learned LVM must recover the structure needed for decision-making — fitting the data well is not sufficient. Identifiability specifies the conditions under which this recovery is possible.
Why observational data?
Historical decisions and outcomes can hasten personalization, reducing the amount of online exploration required for a new instance.
Sequential decision-making algorithms such as multi-armed bandits can find optimal personalized decisions, but are notoriously sample-hungry. To combat this, latent bandits offer rapid exploration and personalization beyond what context variables alone can offer, provided that a latent variable model of problem instances can be learned consistently. However, existing works give no guidance as to how such a model can be found.
In this work, we propose an identifiable latent bandit (ILB) framework that leads to optimal decision-making with a shorter exploration time than classical bandits by learning from historical records of decisions and outcomes. Our method is based on nonlinear independent component analysis that provably identifies representations from observational data sufficient to infer optimal actions in new bandit instances.
Identifiable latent bandits use observational histories from previous instances to learn the hidden structure shared across individuals. The learned representation is then used online to infer a new instance's latent state from repeated contexts and choose actions with less exploration. We verify this strategy in simulated and semi-synthetic environments, showing substantial improvement over online and offline learning baselines when identifying conditions are satisfied.
1
We introduce identifiable latent bandits, ILB, the first family of latent bandit algorithms that recover a continuous vector-valued latent state without requiring the latent variable model (LVM) to be known a priori.
2
We build on nonlinear independent component analysis (ICA) for identifiable representations and introduce mean-contrastive learning and use it to provably learn the LVM.
3
We prove that this framework is partially identifiable to a degree sufficient for optimal decision-making and propose three algorithms that exploit the latent variable model for personalized sequential decision-making in the regret minimization setting.
4
Our experiments show that, when identifying conditions hold, our algorithms improve over online bandits and offline regression baselines in synthetic and semi-synthetic treatment environments.
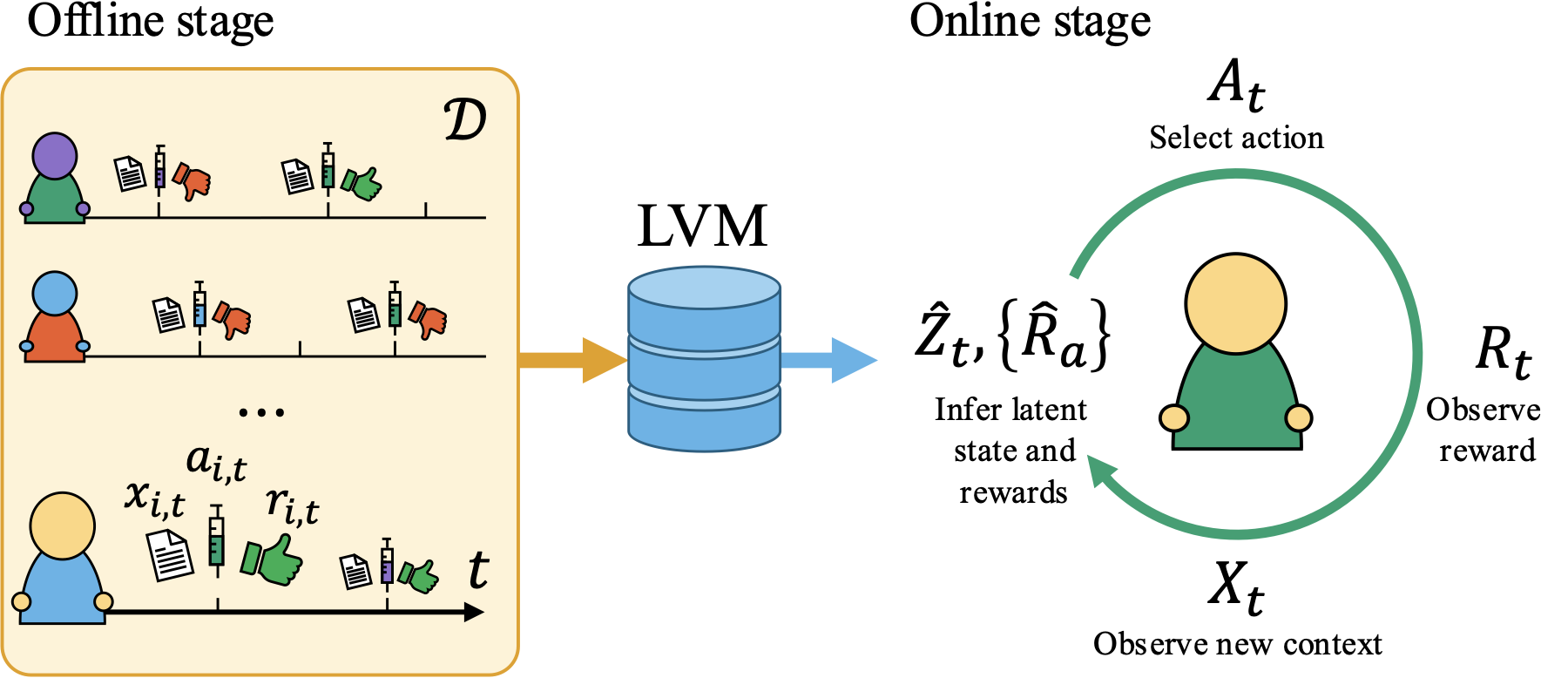
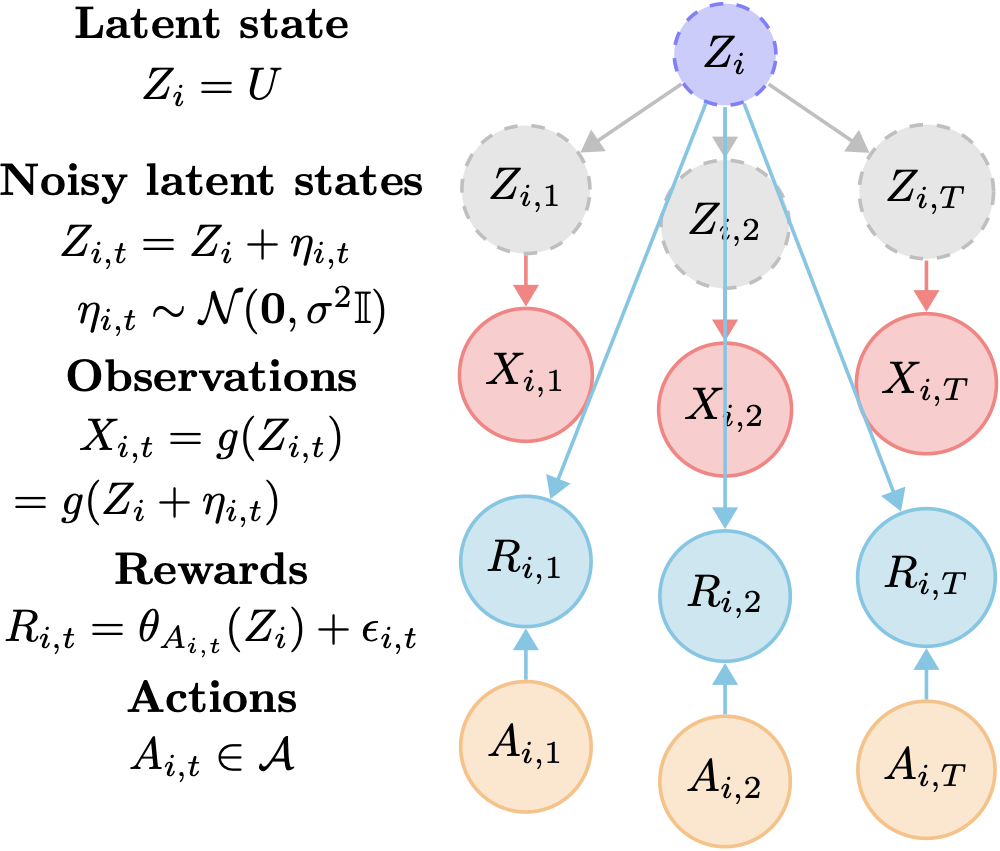
In the offline stage, we learn from historical records of instance data using our mean contrastive objective: given a context observation, predict which historical instance generated it. For our identifiability guarantees we assume that each instance is generated according to strucutral equations given below.
Once this feature extractor is learned, repeated contexts from an instance can be averaged in representation space to estimate the latent state. A reward model is then fit from inferred latent states and observed rewards, giving action-value estimates for online decision-making.
For a new instance, we estimate the latent state using the learned LVM on observed contexts. Online algorithms then use this latent-state estimate with the learned reward model to choose actions, so personalization can start from structure learned across previous instances instead of from scratch. The methods differ in how much online evidence they use. CPG is a simple context-posterior greedy method, FPG refines the latent-state estimate using observed rewards, and FPG-TS samples from the posterior to keep exploration when the learned model is uncertain or biased.
CPG
Uses the average learned representation of observed contexts to estimate the latent state, then acts greedily under the offline reward model.
FPG
Refines the latent-state estimate using both context history and observed rewards, making it more adaptive when the representation is biased.
FPG-TS
Samples reward means under the posterior to trade off fast personalization with recovery from uncertainty or misspecification.
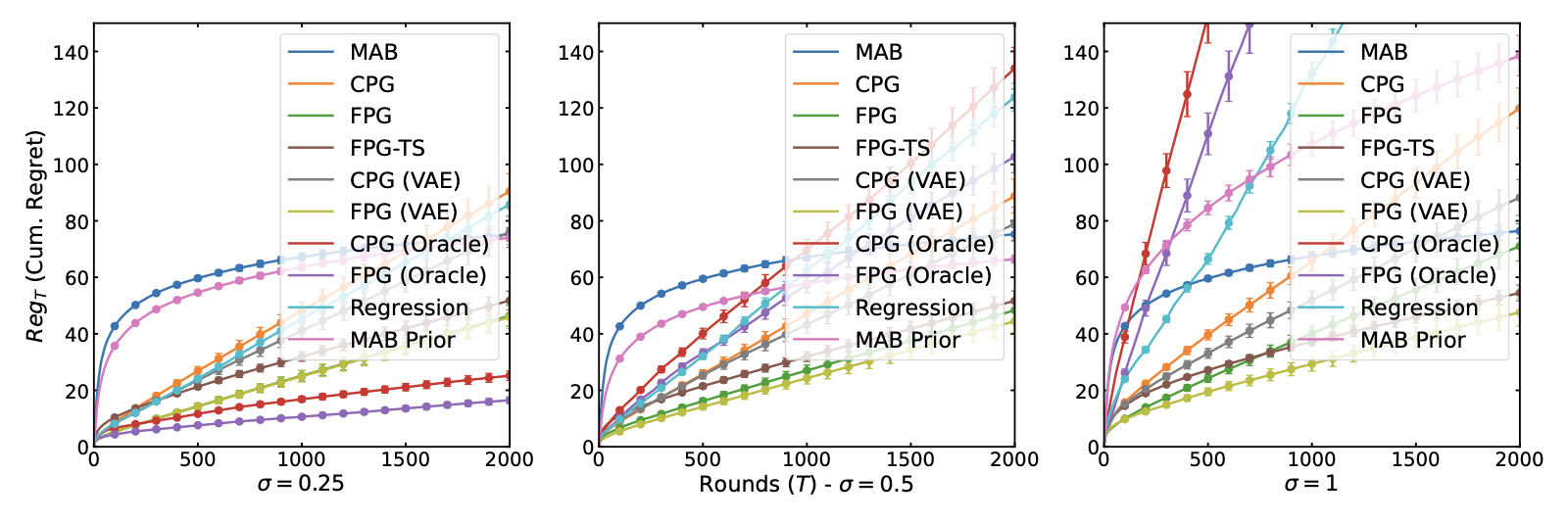
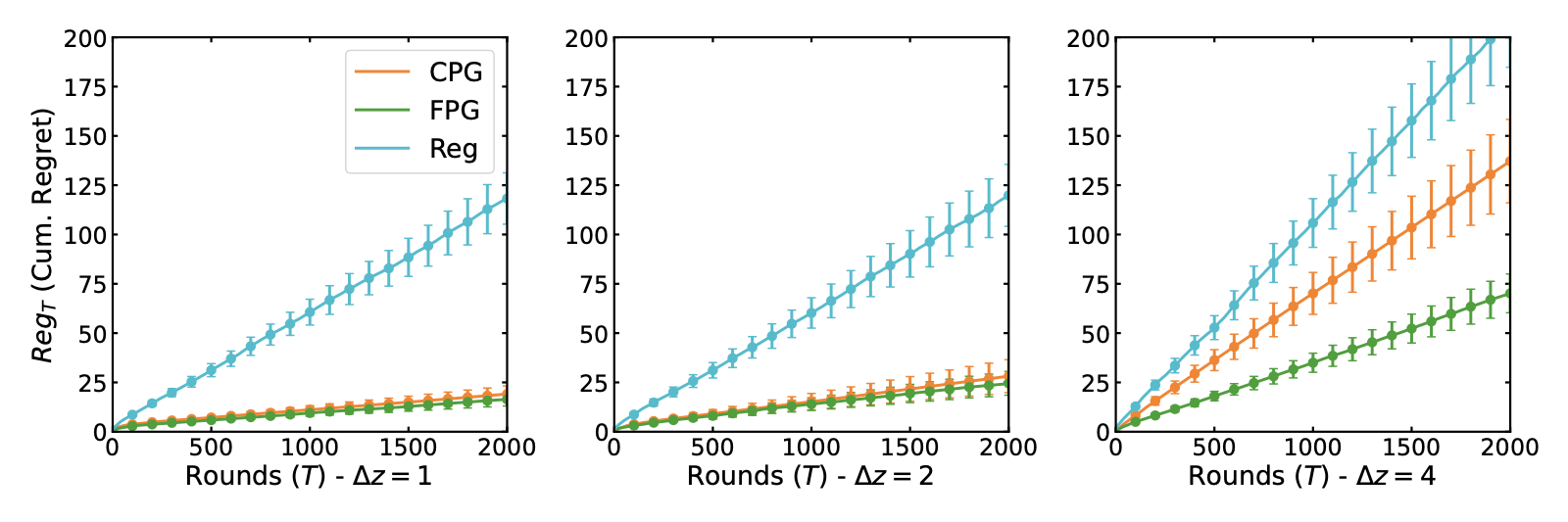
We show results in synthetic and semi-synthetic Alzheimer's disease treatment environments, identifiable latent bandits converge faster than fully online bandits and avoid much of the bias seen in direct regression baselines when the identifying assumptions hold. The experiments also map the limitations: as latent-state noise, context noise, out-of-distribution shift, or the number of arms increases, the tradeoff between fast offline transfer and unbiased online exploration becomes more visible.


@article{balcioglu2026identifiable,
title = {{Identifiable Latent Bandits}: Leveraging observational data for personalized decision-making},
author = {Balc{\i}o{\u{g}}lu, Ahmet Zahid and Mwai, Newton and Carlsson, Emil and Johansson, Fredrik D.},
journal = {Transactions on Machine Learning Research},
year = {2026},
url = {https://openreview.net/forum?id=SvkZ76wKpu}
}